
Identifying adversarial key themes and messages is an important step in analyzing online disinformation campaigns. Using AI can help automate the process of detecting novel key themes and messages. That is where KeyBERT comes in!
What are narratives, themes, and messages?
Narrative – A way of presenting a situation or events that reflect a particular point of view with reasonable or believable logic.
Theme – is a distinct, unifying idea that supports a narrative. Key themes represent broad ideas such as love, patriotism, or ‘us versus them’ narratives.
Message – is a narrowly focused communication directed at a specific audience to support a specific theme. Key messages are similar to business slogans. Some examples of key messages include “No taxation with representation,” “only you can prevent forest fires,” and “Have it your way!”. Key messages will often be repeated by adversaries in order to indoctrinate target audiences to the ideas that are being disseminated.
How can we use KeyBERT to automatically detect key themes and messages?
Bidirectional Encoder Representations from Transformers (BERT) is a family of language models introduced in October 2018 by researchers at Google and KeyBERT is a minimal and easy-to-use keyword extraction technique that leverages BERT embeddings to create keywords and keyphrases that are most similar to a document. Your can learn more about KeyBERT here.
I will now demonstrate how KeyBERT can be used to identify key themes and messages within a corpus of text. As with most large language models (LLMs) KeyBERT can be computationally intensive so I encourage you follow along on a google colab notebook where you will have free access to GPU processors by selecting one of the GPU options in the change runtime type menu when you connect to a runtime.
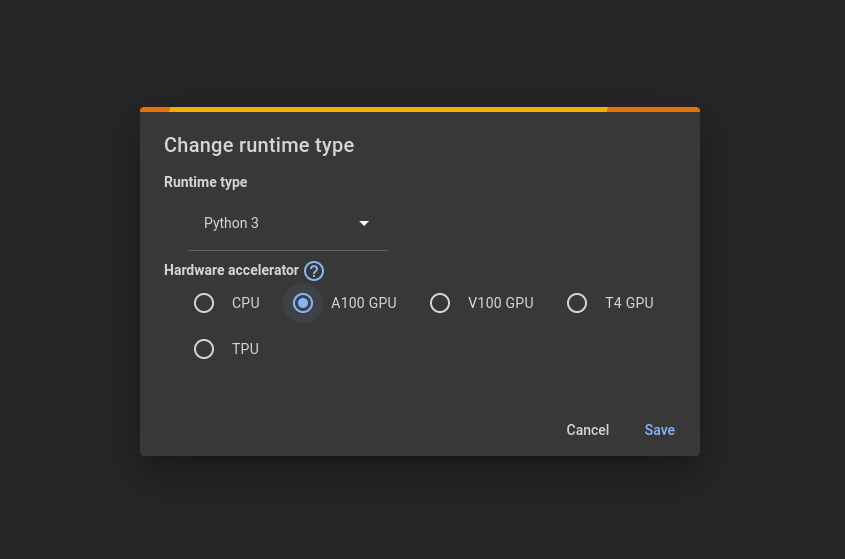
Google colab runs instances of Jupyter notebooks that are preloaded with important data science tools but we will need to install KeyBERT with the following command in order to use it:
!pip install keybertWe will also need to import the matplot libraries in order to do some data visualization:
import matplotlib.pyplot as plt
import numpy as np
import itertoolsWe also need some text to analyze. For this example I chose the book Moby Dick in its entirety because it is a sufficiently long corpus, it is available for free here (just save it as a .txt file), and it is a complex text which will demonstrate the robustness of this text analysis method.
Upload your txt file to your colab notebook clicking on the file section on the left side.
Next we will read our file into the notebook as a string.
# Read Moby Dick in as a single doc
with open("mobydick.txt", "r") as file:
doc = file.read()We want to clean the text up some by removing unnecessary white-space and making all the words lowercase for better processing.
doc = doc.strip()
doc = doc.lower()No we can use keyBERT to download the LLM that we want to use. For identifying the key themes we will stick to the default model of keyBERT which is ‘all-MiniLM-L6-v2’.
from keybert import KeyBERT
# Use the keyBERT default model
kw_model = KeyBERT()Now we can extract the key themes from Moby Dick using the following code snippet. In the arguments I indicate an ngram length of 1-3 which represents the 1 to 3 word length of an ideal key theme. We also compare these short phrases to the entire text document. This is because we are looking for overarching themes so we want to compare the 1 to 3 word phrases to the entire book of Moby Dick to determine lexical similarity. We also change the top_n from the default 5 to 10 so that we get more output.
doc_embeddings, word_embeddings = kw_model.extract_embeddings(doc, keyphrase_ngram_range=(1,3))
keythemes = kw_model.extract_keywords(doc, doc_embeddings=doc_embeddings, word_embeddings=word_embeddings, keyphrase_ngram_range=(1,3), top_n=10)The output reveals that our key themes for Moby Dick are: (numbers indicate cosine similarity)
[(‘forswearing sea tempted’, 0.5305), (‘sea usages instinctive’, 0.4956), (‘sea tempted’, 0.4735), (‘honouring whalemen think’, 0.4712), (‘subtleness sea dreaded’, 0.4683), (‘seas wearily lonesomely’, 0.464), (‘sea tempted day’, 0.4603), (‘whaleman discretion’, 0.4601), (‘read fate whalemen’, 0.4598), (‘whaleman discretion certain’, 0.455)]
Without knowing anything about Moby Dick we can see from this output that it is probably about the sea and whaling.
Next we want to analyze the text for key messages. To do this we first need to convert our single large string into a list of sentences. We do this with the following code snippet.
sentences = doc.split(".")This list of sentences will allow KeyBERT to analyze the phrases by comparing them to their individual sentences rather than the whole text.
We also want to update our LLM from the default to phrase-bert which is a model that is fine-tuned to analyze smaller phrases that you can read more about here.
kw_model = KeyBERT('whaleloops/phrase-bert')Now we can analyze the text for key messages. For this we want to change our ngram range to 3 to 7 and we want to leave stop words in the text by setting them to None. KeyBERT removes the stop words by default but we want to detect complete phrases so that we can conduct frequency analysis.
doc_embeddings, word_embeddings = kw_model.extract_embeddings(sentences, keyphrase_ngram_range=(3,7), stop_words=None)
keymessages = kw_model.extract_keywords(sentences, doc_embeddings=doc_embeddings, word_embeddings=word_embeddings,keyphrase_ngram_range=(3,7), stop_words=None)This step can take sometime. When I ran it on a V100 GPU in colab it took 4 minutes. On a CPU it will take much longer and could crash your kernel.
Because key messages tend to be repeated over and over we will want to combine our KeyBERT detection with frequency analysis in order to identify which phrases are truly the key messages within the corpus. This code snippet conducts frequency analysis. Storing values in a python dictionary will ensure that repeats are not duplicated.
# Evaluate number of occurences of key messages in Moby Dick text
key_val = {}
for items in keywords:
for item in items:
key_val[item[0]] = doc.count(item[0])After storing key phrases and the number of their occurrences in a dictionary we can sort the values to see which ones occur most frequently.
keys = list(key_val.keys())
values = list(key_val.values())
sorted_value_index = np.argsort(values)
sorted_value_index = np.flip(sorted_value_index)
sorted_dict = {keys[i]: values[i] for i in sorted_value_index}Use the following code to truncate this sorted dictionary to create a cleaner plot. 20 items should be relevant enough for this data set. Experiment with that value for other datasets.
short_sort = dict(itertools.islice(sorted_dict.items(), 20))Now we can visualize this information with matplot.
phrases = list(short_sort.keys())
occurences = list(short_sort.values())
fig = plt.figure()
plt.barh(phrases, occurences, color='green')
plt.gca().invert_yaxis()
plt.xlabel("Number of Occurences")
plt.ylabel("Detected phrases")
plt.title("KeyBERT Analysis Results")
plt.show()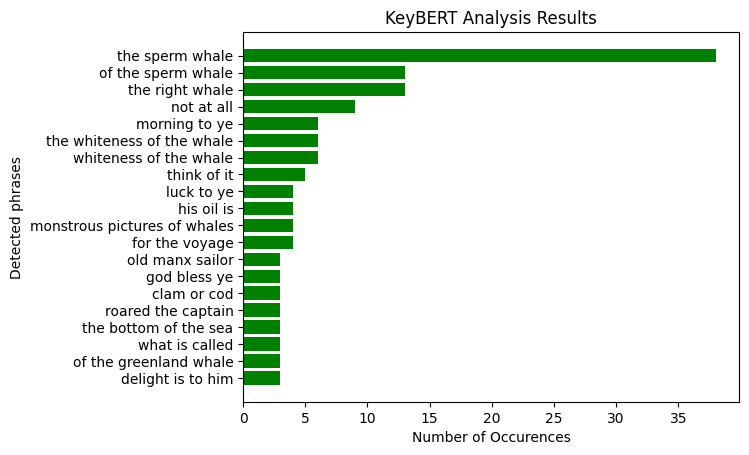
And there you have it! Clearly the key message in the book Moby Dick is “the sperm whale”. This is about what you would expect from a novel about 19th century whaling.
Classical literature is not the only thing that this technique can be used to analyze. It performs well on analyzing social media posts. Below is a word cloud of the key themes I was able to identify by using this technique to analyze over 42,000 Q-Anon related tweets.
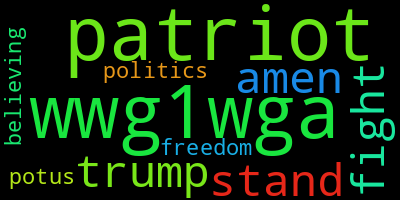
And here are the key messages I was able to identify from those same tweets.
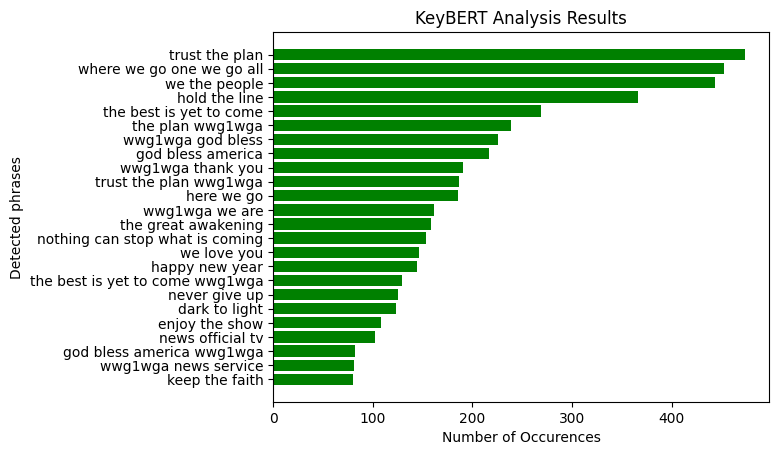
I encourage you all to test this technique on any data that you may have collected to see what sort of interesting results it may reveal!
The code for this example is available here.