
Videos uploaded to the internet are often the preferred medium of choice for the dissemination of disinformation. However, analyzing videos can be tricky as they are a multi-modal medium combining audio and visuals. Transcribing the dialogue of a disinformation video can enable us to use natural language processing (NLP) tools to analyze the resulting text. This tutorial will explain how to use several research tools including yt-dlp, ffmpeg, and openAI-whisper to download disinformation videos and extract the dialogue for text processing.
After YouTube’s crackdown on disinformation in the wake of the 2016/2020 foreign election interference and COVID-19 disinformation campaigns on its platform new streaming services have popped up that allow the hosting of disinformation products. One such platform is rumble, a video streaming platform that allows users to post on a number of topics including politics, sports, and gaming. The platform has no qualms about hosting disinformation products as seen by the 2022 “docuseries” on COVID-19 disinformation hosted here. This is a good place to pull disinformation videos for the use in this tutorial.
Download the Video
The first step in transcribing a video for text analysis is to download the video. To download videos from the internet we can use a tool called yt-dlp. Yt-dlp is a fork of the tool youtube-download which was designed to, you guessed it, download videos from youtube. You can learn more about yt-dlp here.
DISCLAIMER: There is some gray area with downloading videos from the internet. This tutorial is strictly for education/research purposes and is not meant to teach you to do anything nefarious. Remember to always give credit where credit is due and site your sources.
First we need to install yt-dlp so open a terminal on you linux research machine and type the following command. (You can also run all the linux commands in google colab, just add an ! in front of the command).
pip install yt-dlpAfter the installation is complete you should be able to use the tool. Copy the url of the video you want to download and download it using the following command, replace the <url> tag with your url.
yt-dlp <url> -o file_name.mp4Adding the -o (output) file_name.mp4 gives you a cleaner output. Change file_name to what you want to call your video. If your download is interrupted just run the command again, it may take a couple tries.
Extract the Audio
Next we need to convert the video file to an audio file. We can do this with the tool ffmpeg. Ffmpeg is a powerful command-line media processing tool. I encourage you to read the docs to see all of its capabilities.
Install ffmpeg in linux with the following command.
pip install ffmpegConvert your video file to an audio file with the following command.
ffmpeg -i file_name.mp4 file_name.mp3Now you can use OpenAI whisper to convert this audio file to a text file.
OpenAI, the folks who brought you ChatGPT, developed whisper as a general purpose speech recognition model. Learn more about it here.
As with all LLMs, it is better to use a GPU as they tend to be more computationally intensive. Free GPUs are available through google colab. Just select the GPU option when you connect to a runtime.
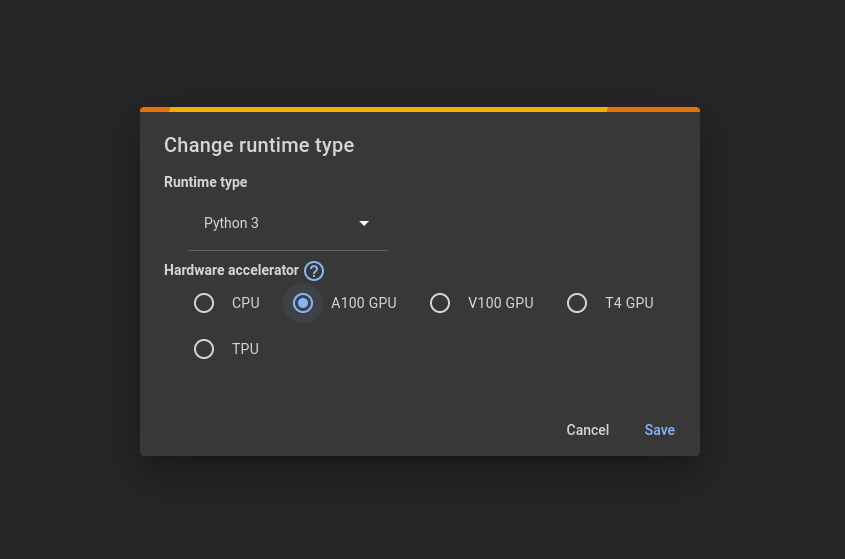
Then upload your audio file to google colab for use.
Next you will need to install openai-whisper in colab (or on your linux machine, exclude the !) with the following command.
!pip install -U openai-whisperNext you will import whisper, load a model, and transcribe your audio file. We will use the ‘medium’ model as it is a happy medium (lol) between efficiency and performance. You can read more about the models on the openai-whisper GitHub page.
import whisper
model = whisper.load_model("medium")
result = model.transcribe("file_name.mp3")Even on a GPU this may take some time to finish. Once complete you can save the audio transcription to a txt file with the following lines of code. (Don’t forget to download the file from colab to save it).
tf = open("file_name.txt", "w")
tf.write(result['text'])
tf.close()Whisper can also be run as a command line tool and has a translate function which can translate the audio as it transcribes it. Here is an example of a translation I did on a Putin speech I downloaded from here. Specify the language with the language tag and the translate tag will translate it to English. If you exclude the language tag it will just transcribe the audio into the specified language. I also specify the model as large which will produce better results but is computationally more intensive. (Remove the ! if you are running this command in a Linux terminal). This command will produce several files, the txt file is the translated transcript. Whisper supports a number of languages, read the docs to find out more.
!whisper putin.mp3 --language Russian --task translate --model large And there you have it! It really is that simple. You now have text that you can apply other analytical techniques to. Happy hunting!